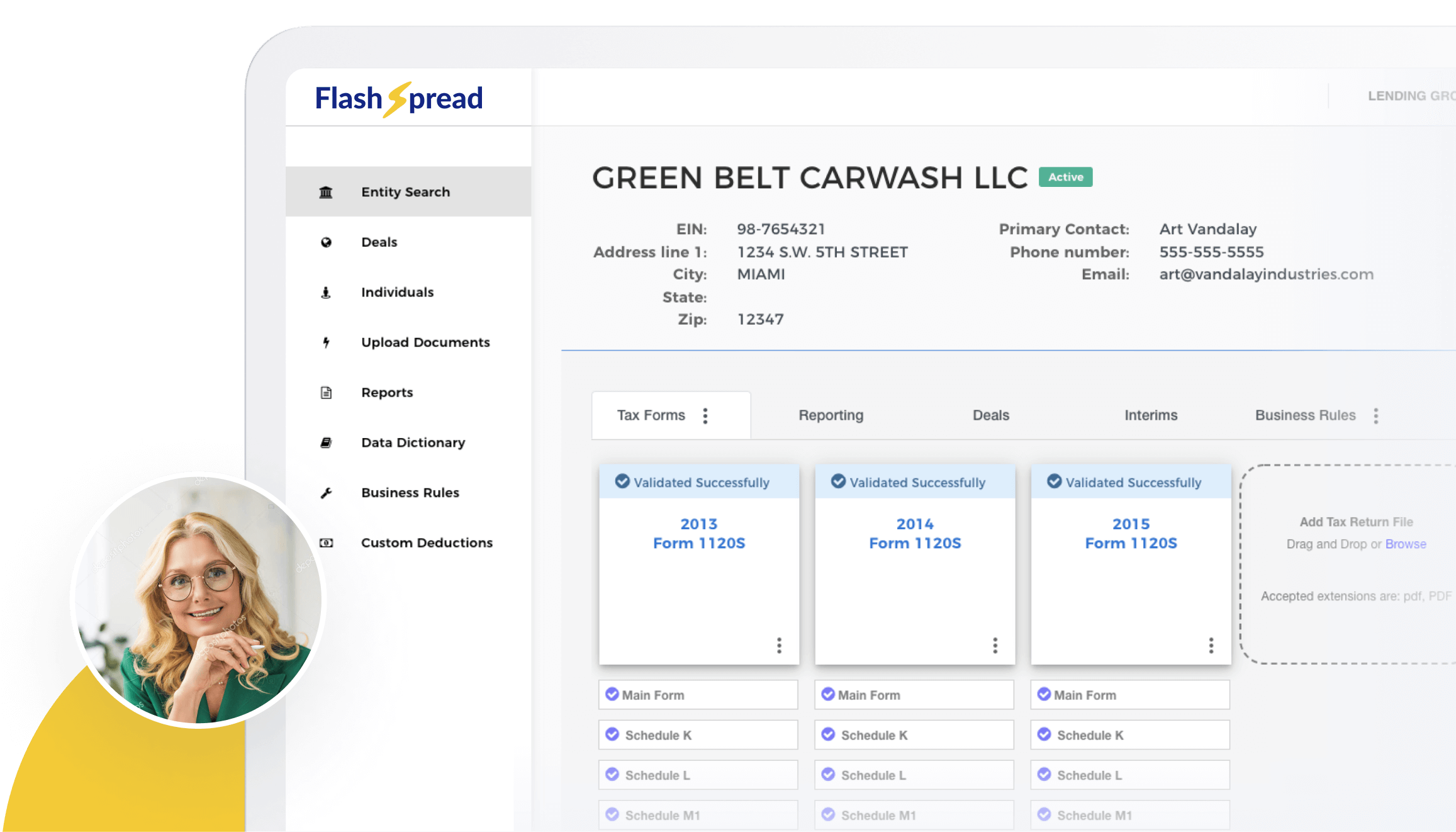
Commercial lenders have spent years trying to reduce the time it takes to prepare borrower financials for analysis. Yet for many teams, document extraction remains one of the most manual and time-consuming parts of the credit workflow.
Borrowers send tax returns, financial statements, rent rolls, debt schedules, and supporting documents as PDFs. Analysts then review those files, locate key values, rekey the data into spreadsheets, standardize the financials, and validate the results before underwriting can begin. Even with OCR tools in place, much of that work often still requires manual review and cleanup.
That is because document extraction is not just about reading text from a page. In commercial lending, it is about turning borrower documents into usable financial data that can support spreading, underwriting, reporting, and monitoring. And that requires more than OCR alone.
This blog explores why traditional document extraction still creates friction for credit teams, where OCR helps, where it falls short, and why more lenders are looking at a layered approach that combines OCR with AI to improve both speed and accuracy.
Key Insights at a Glance
- Document extraction remains a major source of manual work in commercial lending
- OCR helps digitize borrower documents, but it does not solve every extraction challenge
- Credit teams need more than text capture. They need usable, structured financial data
- AI can improve accuracy by helping interpret, organize, and validate extracted information
- Better extraction reduces manual spreading work and improves credit readiness
- FlashSpread combines OCR, machine learning, and AI-enabled workflows to turn borrower documents into decision-ready financial data
Table of Contents
- Why Document Extraction Still Slows Credit Teams Down
- What OCR Does Well
- Where OCR Alone Falls Short
- Commercial Lending Needs More Than Text Extraction
- Why a Layered OCR + AI Approach Matters
- Better Extraction Improves More Than Speed
- How FlashSpread Approaches Document Extraction
- Accuracy Matters Because Rework Is Expensive
- Roundup
Why Document Extraction Still Slows Credit Teams Down
For many lenders, the document workflow still looks familiar.
A borrower submits PDFs. An analyst opens each file, reviews the financials, identifies relevant values, and begins preparing the spread. If OCR is available, it may help pull text from the document, but someone still needs to verify the output, organize the information, map it into the right format, and confirm that the numbers tie out.
This matters because extraction is not a standalone task. It sits at the front of the credit workflow. If the extracted data is incomplete, inaccurate, or poorly structured, the problems do not stop there. They carry into spreading, underwriting, and every downstream process that relies on the financials.
That is why document extraction creates more friction than many lenders expect. It is not only about saving keystrokes. It is about reducing the manual work required to make borrower data usable.
What OCR Does Well
OCR still plays an important role in commercial lending.
At its core, OCR helps convert static borrower documents into machine-readable text. That is an important first step. Without it, lenders would still be relying entirely on analysts to manually read and rekey every value from a PDF.
For structured borrower documents such as tax returns and financial statements, OCR can provide meaningful efficiency gains by:
- Capturing text from static PDFs
- Pulling values from common document layouts
- Reducing some manual data entry
- Helping teams digitize borrower financials faster
This is why OCR remains foundational in many document processing workflows. It helps move financial data out of static files and into a format that can be worked with more efficiently.
But in commercial lending, that is only part of the challenge.
Where OCR Alone Falls Short
OCR can read characters. It does not always understand the financial context.
That distinction matters because borrower documents are not all the same. Even structured financial documents vary in layout, terminology, reporting periods, and formatting. A balance sheet from one borrower may look very different from another. Income statements may use different labels. Supporting documents may not follow a consistent template at all.
As a result, OCR alone can leave credit teams with work still to do:
- Reviewing extracted values for accuracy
- Determining which figures belong in the spread
- Mapping line items into standardized categories
- Resolving inconsistent naming conventions
- Validating totals and relationships between line items
- Identifying missing or misread information
This is where lenders often discover that OCR reduced some manual entry, but not enough of the actual preparation work. Analysts may still spend significant time checking output, correcting errors, and organizing the data before underwriting can begin.
In other words, OCR can help read the document. It does not always help prepare the financials for credit review.
Commercial Lending Needs More Than Text Extraction
Credit teams do not simply need text from a PDF. They need financial data that is accurate, organized, and ready to use.
That means a stronger extraction workflow should do more than capture values on a page. It should help transform borrower documents into structured financial data that can support spreading and underwriting with less manual cleanup.

In practice, that requires the extraction process to handle questions like:
- Which values belong to which financial categories?
- How should line items be standardized across borrowers?
- Which periods should be included in the spread?
- Do totals and subtotals reconcile correctly?
- Are there missing values or inconsistencies that need review?
These are not OCR questions. They are credit workflow questions.
And they are exactly why lenders are starting to think differently about extraction. The objective is no longer just digitizing documents. It is preparing reliable financial data for the decisions that follow.
Why a Layered OCR + AI Approach Matters
The most effective extraction workflows increasingly combine the strengths of OCR with AI and machine learning.
Subscribe to BeSmartee 's Digital Mortgage Blog to receive:
- Mortgage Industry Insights
- Security & Compliance Updates
- Q&A's Featuring Mortgage & Technology Experts
OCR remains valuable for reading the document and converting it into text. But AI can help interpret that extracted information, recognize patterns, improve categorization, and support validation in ways OCR alone cannot.
This layered approach matters because it addresses both parts of the challenge:
OCR helps with document capture
- Reads static PDFs
- Extracts text and values from borrower documents
- Creates the initial digital version of the financials
AI helps with financial interpretation
- Organizes extracted data into usable financial structures
- Improves line-item recognition across varying document formats
- Supports validation and consistency checks
- Helps reduce manual review and cleanup
Together, this creates a stronger path from borrower documents to credit-ready financial data.
That does not mean every document will require zero human review. Credit teams still need oversight, especially for exceptions and edge cases. But it does mean analysts can spend less time rebuilding data manually and more time evaluating the borrower.
Better Extraction Improves More Than Speed
The first benefit of stronger document extraction is usually time savings. Less manual entry means faster spreading and less repetitive work for analysts.
But the bigger benefit is what happens when extracted data is more accurate and more structured from the start.
Better extraction can improve:
- Consistency across spreads
- Underwriting preparation
- Credit memo workflows
- Reporting and dashboards
- Portfolio monitoring
- Visibility across borrower financials
When borrower data is captured and structured more effectively, teams do not have to recreate the same information across multiple steps in the credit process. That reduces rework and makes the broader workflow more scalable.
This is especially important for lenders trying to grow without increasing analyst headcount at the same rate as loan volume. Faster extraction matters, but reliable financial data matters even more.
How FlashSpread Approaches Document Extraction
FlashSpread is built around a practical reality of commercial lending: borrower documents still arrive as PDFs, and lenders need a faster way to turn those documents into usable financial data.
That is why FlashSpread uses a layered approach that combines OCR, machine learning, and AI-enabled extraction workflows.
OCR helps read the document. From there, FlashSpread helps extract, organize, and standardize the financial data so it can be used in spreading and underwriting with less manual preparation.
With FlashSpread, lenders can:
- Extract financial data from tax returns, financial statements, and supporting borrower documents
- Reduce manual rekeying and spreadsheet preparation
- Organize borrower financials into standardized spreads
- Improve consistency across reviews
- Support faster underwriting preparation with cleaner data
The goal is not simply to digitize a PDF. It is to reduce the manual work required to prepare borrower financials for analysis.
And once that data is structured, it can support more than the spread. It can help create a stronger foundation for underwriting, reporting, portfolio monitoring, and broader credit workflows.
Accuracy Matters Because Rework Is Expensive
One of the biggest hidden costs in document extraction is not the initial pass. It is the rework that happens afterward.
If extracted values are misread, mislabeled, or poorly organized, analysts still have to step in and correct the output. That means the workflow has not really been simplified. The manual work has just moved to a different point in the process.
This is why accuracy matters so much in commercial lending extraction workflows. A lender does not gain much by pulling data out of a PDF quickly if the output still requires heavy cleanup before it can be used.
The best extraction workflows reduce both manual entry and manual correction. They help teams move closer to decision-ready financial data, not just partially digitized documents.
Roundup
OCR remains an important part of commercial lending document extraction, but it is no longer enough on its own.
Credit teams are not simply trying to read PDFs faster. They are trying to reduce the manual work required to prepare borrower financials for spreading and underwriting. That means extraction has to do more than capture text. It has to help create accurate, structured financial data that can support the rest of the credit workflow.
That is why more lenders are looking at a layered approach that combines OCR with AI and machine learning. OCR helps capture the document. AI helps organize, validate, and improve the extracted data so analysts spend less time on cleanup and more time evaluating risk.
If your team is still spending hours preparing borrower financials, it may be time to rethink document extraction. See how FlashSpread helps lenders turn borrower documents into decision-ready financial data faster.